Bluesky: Loading...
As posted about on the Vantage blog, we rewrote the ec2instances website to be significantly quicker. This wasn’t without technical challenges, and overcoming them has been one of the best things I have ever done in my career. I am really hyped about how this turned out, and the roadmap looks amazing due to the rapid iteration.
You can check out the website here and the codebase here. I think we did a great job!
The old codebase
Initially, we were going to keep adding features and optimisations to the old codebase. After all, unless you need to, there are major disadvantages to rewriting a codebase. We needed to add over a decade of legacy behaviour whilst also keeping up with feature requests we get in the meantime. However, it quickly became clear that iterating on the old codebase for new features may actually take more energy than just performing the rewrite for everyone:
- The multi-thousand line jQuery based file that powered the full site was full of bugs and edge cases (as are most decade old code files). Whilst it served Vantage very well for many years, understanding it was hard enough, yet alone adding to it.
- The old codebase had a very complex build process. The CSS and HTML build process was split in such a way that it became quite complex to develop for. Additionally, over the years the process got fragmented across different methods of building.
- The old codebase relied on DOM manipulation. This caused fragile code and also meant the HTML for the index for example was over 10MB. This is a lot of HTML for a browser to parse, locking up the main thread! Additionally, column changes froze up the whole application for multiple seconds on Firefox. The site was never designed to be this size, and it showed in how it performed.
We decided we wanted to generate the content statically, and we wanted a framework that could carry us nicely with RSC support. We went with Next.js using App Router. And so, the rewrite began!
Building the base
Alongside Next.js, we decided we wanted to use the following other technologies to build the tables part of our product:
- Cloudflare: Very strong global presence and allowed us to deploy our static content fairly easily.
- Tanstack Table: Pretty nice table implementation. We needed a implementation that wouldn’t lead as easily to the code fragmentation we had with the previous codebase, so this was a natural choice.
- Tailwind: Allows us to be able to build up the UI in a way that allowed for rapid iteration.
With our technology stack set, we got to building. We wanted to use the old scraping code still, but the rest I got to building without in another branch. Porting all the columns was the most complex part of this. I found some tricks to make Cursor list out most of them properly by pointing it to the HTML element holding all of the items, but there was still significant human intervention required to make all the columns work properly. Additionally, there was a lot of bugs that had to be ironed out. This is code that is over a decade old, with many rows.
We very quickly realised we would need Tanstack Virtual too since we didn’t want to end up in the same performance predicament as pre-rewrite when it came to performance. Changing columns with this was near instant.
As for loading in the content, I made it show a loading spinner, but we realised we could do better by loading a chunk of the data inside the page and then loading the rest as a MessagePack blob. One problem we encountered was that we want the blobs to be really small for caching reasons. Luckily, the xz-decompress library helped with this by using a literal version of libxz inside WebAssembly (I am very aware of the situation recently, this library is so old it does not affect us and even if it did it won’t execute in WASM), and we could pipe it as a readable stream directly into the MessagePack library we were using and get a streamed decode. We then cached the tables loaded content should the user wish to navigate back to it.
Initially, this is all we did, stream in N instances at a time by invoking useSyncExternalStore’s change function every time a chunk was done (my favourite React hook, and a deeply underrated one in my opinion). This was already significantly quicker than the old website, but I thought we could do better.
Multi-threading in JS
There is a myth that browser JS always has to run on a single thread. Whilst there is some truth to this (I know, I know, under the hood V8 has multiple threads and it does scheduling, but for the context of what the user experiences: 1 thread), you can spawn “web workers”. You can think of these like spawning a new process on a OS, they have their own space but they can access shared content. They also have a pipe to communicate to who spawned them. This means that we do not block the main thread, which means the user feels it far less.
Initially, I just took the single file code and turned it into a web worker. Whilst this did significantly speed up performance, I couldn’t scratch the feeling we could do even better.
The first attempt at this was to split the file into 10 parts and just return each part when it is fully done (rather than loading in chunks since this would with 10 parts actually cause more re-renders that could hurt performance). This was getting near instant now and worked really well, but in one last squeeze that helps users on slower systems, I went ahead and split out decompression to another worker that fed the deserialization worker since we hit a point where they were blocking each other. This was perfect now performance wise (especially with Tanstack Virtual which allows us to specify the size the table should be).
Whilst this was awesome, I did happen to notice that a big chunk of the data was pricing information. We reduced the bandwidth we use even further (and even get a smaller performance win) by compressing the pricing data in a domain specific way. This even meant we could reuse strings for the keys from an initial list. A nice win for bandwidth!
Appeasing our robot overlords
Like it or not, AI has became a part of technology, and being as we want to give all users the best experience possible, we need to support this. AI’s cannot read or interact with our table nicely due to their context windows, so we made an llms.txt which they can understand.
The file links to multiple indexes. The goal is to get the AI to the information in as few hops as possible. To do this, we index by various things such as regions, cost, and series types. Testing done with my companies proprietary tooling (which you should be hearing about in the future!) looks promising, and any service that uses the llms file should be able to crawl this website significantly easier than the old one.
My one gripe with Next.js is I do wish we could build this within the context of the Next application. Unfortunately, you cannot pass static parameters to a GET route, so we couldn’t bulk build this context.
The information pages
We then needed to write the information page for each instance. Luckily, Next’s SSG logic does make this very easy. To handle this, we simply load the content, then we pass in the slugs and for each slug we get back load the information for it. From there, we pass it to the page with all the server information. We include a compressed version of the pricing data too, which is dynamically decompressed by the pricing calculator logic. We wrote the data to go into the tables in a standardised way so that it could be used by the LLM logic too, and then once I got the structure setup nicely, it was fairly easy to port to the other information pages. Overall, minus some details and the pricing calculator, this was one of the simpler parts of the website to create thanks to SSG.
Image generation is done outside of Next (for the gripe listed above), but to do so, we use the sharp library and multiple child processes to handle creating the images. It works okay. The library is nice, just one day this might become Go/Rust because it is quite slow and we know what we need here.
Deployment, caching, and routing
For production and staging, we are using Cloudflare Workers to handle routing to our Workers KV and R2 buckets which are hosting data. We have a Worker to handle all of the Next cases (such as 404.html and the root path), which we keep in the root of the repository. We can’t use Wrangler to deploy the entire site because of the tiered storage we need for larger files, so we settle for using wrangler to deploy the worker and a bunch of TS to deploy the rest of the site. It works pretty nicely. In the worker, we also write to the cache and read from it, allowing a very high cache rate.
We are using make, nvm, and Docker to handle development standardisation. This means that whatever platform you run the build on, it should behave the same. This makes it far easier to develop for, and you can also go ahead and download the scraped data rather than running the scraper itself, saving significant time for developers.
The end result
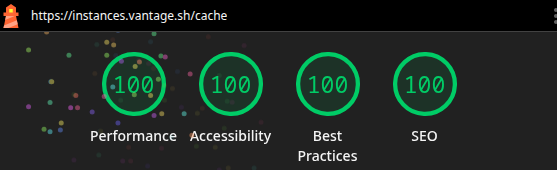
And so, on May 23rd, we cut over the DNS to Cloudflare and pushed everything to the public repository. With that, the rewrite was live! There was a couple of things that I had to quickly patch because we missed some legacy behaviours (this is a over decade old site, we accidentally removed some old things but added them back within a day, sorry if you hit this!), but it was mostly an extremely smooth migration. Development was fairly fast thanks to the rapid iteration allowed by Turbopack and the Next.js app router.
Additionally, using modern frameworks means we are able to fix problems really fast. We are finding many solutions to problems in under half an hour, which is amazing for our users.
Accessibility is also much nicer on the new site too! React has such a great ecosystem of accessible components, accessibility testing with axe is far easier to do than with the old codebase (and we are starting to introduce this), and we have tested our code is accessible using a screen reader (tested with VoiceOver on macOS).
Overall, we are really proud of this release. Here’s to confetti!